Domain adaptation with Xception and VGG16 models
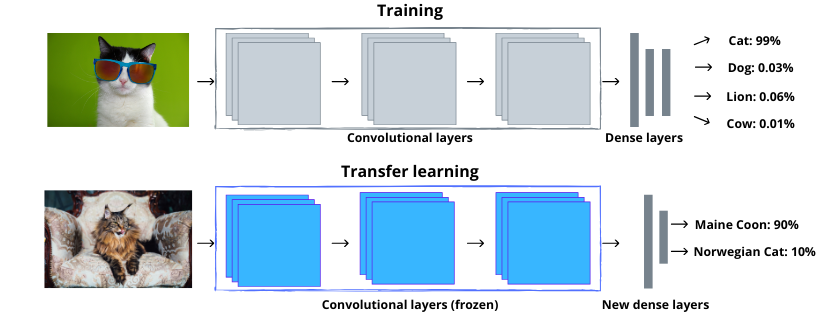
Rozpoczynając przygodę z algorytmami sztucznej inteligencji, warto postawić sobie dwa podstawowe pytania:
- Jaki problem chcielibyśmy rozwiązać?
- Jak zbudować model, który nam to umożliwi?
Jeśli chodzi o pierwsze pytanie, to ogranicza nas jedynie wyobraźnia i dostępność danych, które możemy wykorzystać do uczenia modelu. Jeśli chodzi o pytanie drugie to wybór modelu zależy w znacznej mierze od rozwiązywanego problemu, zasobów sprzętowych jakimi dysponujemy oraz czasu, w jakim chcielibyśmy skończyć nasze zadanie.
Najlepiej to pokazać na przykładach. Załóżmy, że chcemy stworzyć algorytm wspomagający poprawną segregację odpadów na podstawie zdjęcia. Jeśli chodzi o sam dobór algorytmu, to w tym przypadku mamy kilka opcji. Możemy wykorzystać lasy losowe drzew decyzyjnych lub maszynę wektorów nośnych po uprzednim wyekstrahowaniu odpowiednich cech z obrazu. Możemy też wykorzystać splotowe sieci neuronowe, które operują bezpośrednio na danych obrazowych. Architekturę takiej sieci możemy zaprojektować sami,na wstępie warto jednak rozważyć adaptację gotowego modelu, co pozwoli nam zaoszczędzić dużą ilość czasu. Ja do rozwiązania przyjętego problemu zdecydowałam się wykorzystać wstępnie nauczone modele sztucznych sieci neuronowych. Jak będzie to wyglądało w praktyce? Przeprowadzę Was przez ten proces krok po kroku.
Analiza i przygotowanie danych
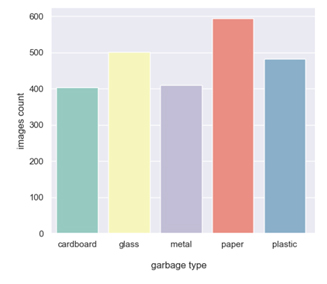
Zbiór danych, z którego postanowiłam skorzystać, znajduje się na stronie: Garbage Classification. Zawiera on zdjęcia odpadów podzielonych na 6 kategorii: karton, szkło, metal, papier, plastik i odpady zmieszane. Ostatnia kategoria zawiera zdjęcia przedmiotów, które w większości mogłyby zostać przyporządkowane do 5 pozostałych grup. Z tego względu wykluczamy ją z dalszej analizy. Poniżej przedstawiony został wykres, na którym widać liczbę zdjęć dostępnych dla każdej z klas.
Bardzo ważnym etapem przygotowania zbioru danych jest jego podział na co najmniej dwa podzbiory: treningowy i walidacyjny. Jeszcze lepszą praktyką jest stworzenie trzech rozłącznych zbiorów danych: treningowego, walidacyjnego i testowego. W tym przypadku rezultaty prezentowane na zbiorze testowym są reprezentatywne i pokazują rzeczywistą skuteczność systemu dla nowych, niewidzianych przez niego wcześniej zdjęć. W moim przypadku 60% zdjęć posłużyło do treningu, 20% stanowiło zbiór walidacyjny, a kolejne 20% trafiło do zbioru testowego. Poniżej znajdują się przykładowe zdjęcia dla każdej z klas. Każde zdjęcie ma rozmiar 512 x 384 pikseli. W przypadku wykorzystywania gotowej sieci neuronowej bardzo ważne jest dostosowanie rozmiaru obrazów w zbiorze do rozmiaru danych wejściowych akceptowanych przez sieć. W przypadku sieci Xception[1] rozmiar warstwy wejściowej to 299 x 299, natomiast w przypadku sieci VGG16[2] rozmiar ten wynosi 224 x 224. Z tego też względu przed przystąpieniem do nauki modelu musimy przeskalować nasze obrazy.

Przygotowanie i trenowanie modeli
Do rozwiązania problemu jaki sobie postawiłam, wykorzystałam dwie, popularne architektury sieci: VGG16 oraz Xception. Obydwa wybrane przeze mnie modele uczone były na zbiorze ImageNet[1], który zawiera zdjęcia obiektów należących do 1000 klas. W związku z powyższym warstwa wyjściowa, odpowiedzialna za klasyfikację wejściowego obrazu posiada 1000 wyjść. W przypadku analizowanego przeze mnie problemu wielkość warstwy wyjściowej powinna wynosić 5. Poniżej znajduje się kod, który umożliwia przystosować wstępnie przetrenowany model do mojego zbioru danych.
# model adaptation
20 base_net = tf.keras.applications.xception.Xception(weights='imagenet')
21 # base_net=tf.keras.applications.vgg16.VGG16(weights='imagenet')
22 base_net_input = base_net.get_layer(index=0).input
23 base_net_output = base_net.get_layer(index=-2).output
24 base_net_model = models.Model(inputs=base_net_input, outputs=base_net_output)
25
26 for layer in base_net_model.layers:
27 layer.trainable = False
28
29 new_xception_model = models.Sequential()
30 new_xception_model.add(base_net_model)
31 new_xception_model.add(layers.Dense(5, activation='softmax', input_dim=2048))Ze względu na niezbyt duży zbiór danych przy uczeniu modelu zastosowałam zwiększenie liczby danych uczących (ang.data augmentation). Poniżej znajduje się fragment kodu, odpowiedzialnego za trening wybranego modelu
# hyperparameters
34 base_learning_rate = 0.0001
35 opt = optimizers.SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True)
36
37 new_xception_model.compile(optimizer=opt,
38 loss='sparse_categorical_crossentropy',
39 metrics=['accuracy'])
40
41 # data preparation and augmentation
42 train_data_gen = ImageDataGenerator(
43 rescale=1. / 255,
44 shear_range=0.2,
45 zoom_range=0.2,
46 horizontal_flip=True)
47
48 valid_data_gen = ImageDataGenerator(rescale=1. / 255)
49
50 train_generator = train_data_gen.flow_from_directory(
51 directory='training_data',
52 target_size=img_dim,
53 color_mode="rgb",
54 batch_size=batch_size,
55 class_mode="sparse",
56 shuffle=True,
57 seed=42
58 )
59
60 valid_generator = valid_data_gen.flow_from_directory(
61 directory='validation_data',
62 target_size=img_dim,
63 color_mode="rgb",
64 batch_size=batch_size,
65 class_mode="sparse",
66 shuffle=True,
67 seed=42
68 )
69
70 # model training
71 garbage_recognition_model = new_xception_model.fit_generator(generator=train_generator,
72 validation_data=valid_generator,
73 epochs=epochs,
74 callbacks=[checkpoint, tensorboard_callback, earlyStop]
75 )
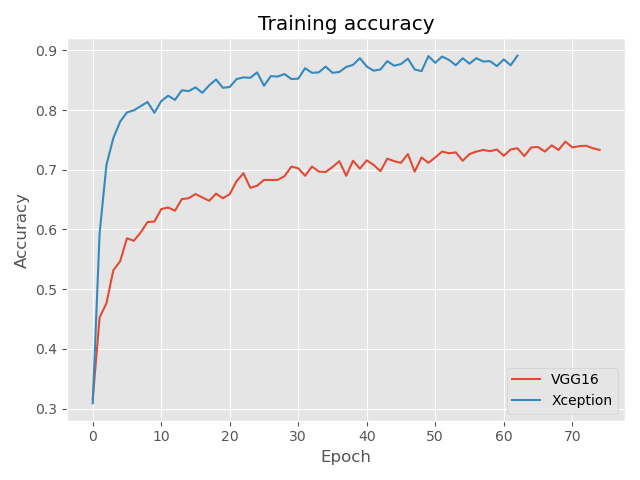
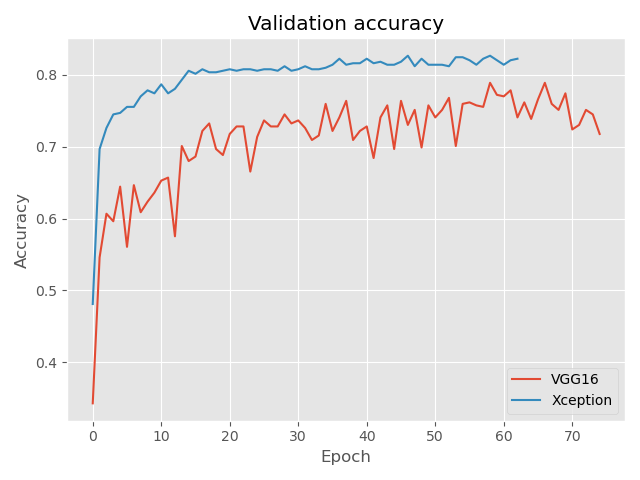
76 Podczas trenowania wybranych modeli zastosowałam wczesne zatrzymanie uczenia (ang. early stopping). Polega ona na tym, że jeśli skuteczność rozpoznawania zdjęć ze zbioru walidacyjnego nie wzrasta przez określoną liczbę epok, to uczenie zostaje przerwane. Stosowanie tego typu podejścia zmniejsza ryzyko dopasowania modelu do danych uczących (ang. overfitting). Poniżej przedstawione zostały krzywe uczenia dla zbioru treningowego i walidacyjnego. Widoczne jest, że w tym przypadku znacznie lepiej poradziła sobie sieć Xception, pozwalając na uzyskanie ponad 80% skuteczność rozpoznawania zdjęć ze zbioru walidacyjnego.
Skuteczność stworzonych rozwiązań
Jak wspominałam wcześniej określenie rzeczywistej skuteczności naszego modelu najlepiej wykonać na nowym zbiorze danych, które nie brały udziału w uczeniu naszych modeli. Dlatego też poniżej przedstawiłam wyniki, jakie udało się uzyskać na zbiorze testowym. Zbiór ten zawierał 480 zdjęć. Wyniki potwierdzają wniosek, że w tym przypadku znacznie lepiej poradził sobie model bazujący na wstępnie przetrenowanej sieci Xception. Uzyskała ona skuteczność 83%, czyli o niemal 10 punktów procentowych więcej niż model oparty o architekturę VGG16.
VGG16
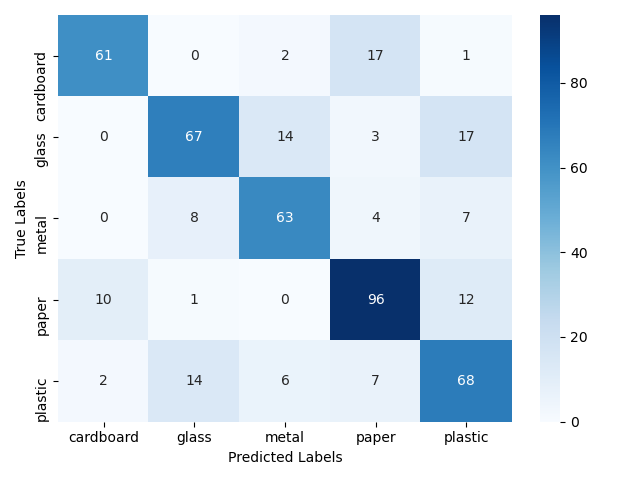
ACC = 74%
Xception
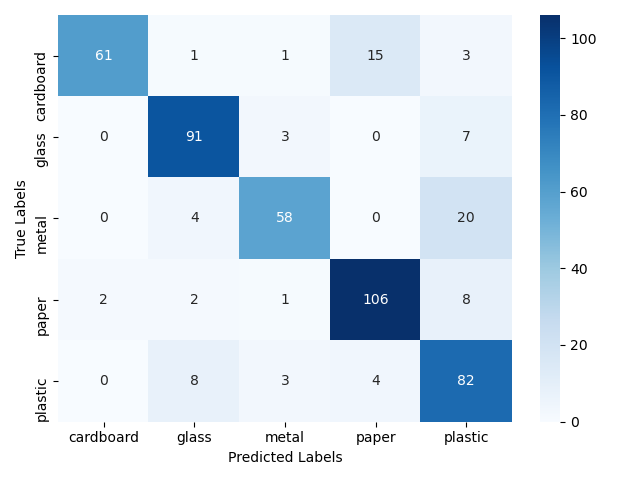
ACC = 83%
Podsumowanie
Artykuł pokazuje, w jaki sposób wykorzystać wstępnie przetrenowane architektury sieci w konkretnym problemie, który chcemy rozwiązać. Opisuje on pokrótce proces analizy i przygotowania danych, zaadaptowania gotowych modeli do swoich potrzeb oraz metody oceny skuteczności stworzonego rozwiązania.
Jest to pierwszy z serii artykułów przeznaczony dla osób chcących rozpocząć swoją przygodę z wykorzystywaniem algorytmów sztucznej inteligencji. Serdecznie zapraszam do śledzenia naszych wpisów na blogu Isolution oraz naszych firmowych profili na LI i FB, a także do zapisania się do naszego newslettera.