Anomaly detection with Autoencoders
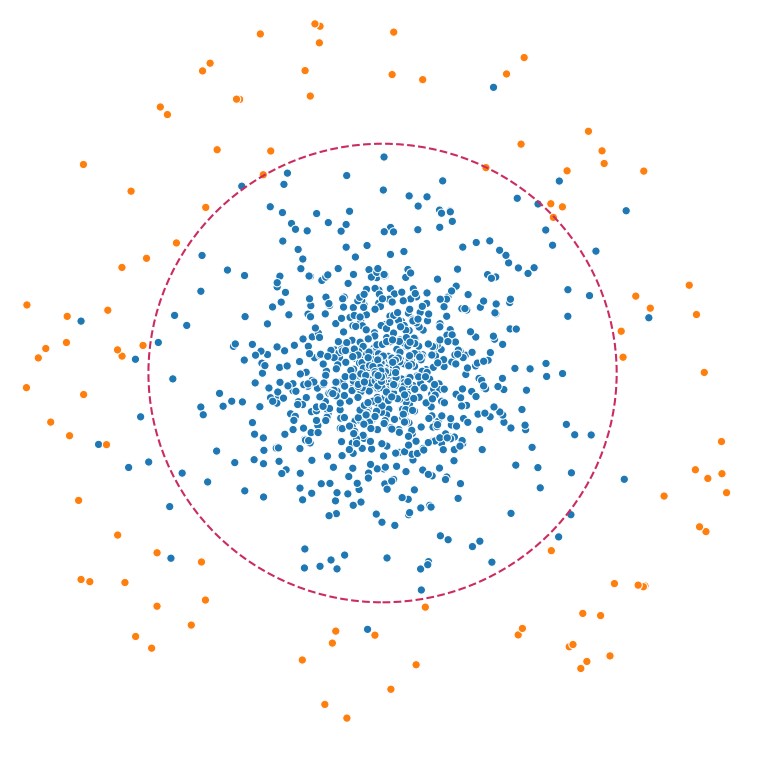
Anomalies in systems occur rarely. The validation layers stand guard over correctness by catching them out and eliminating them from the process. A cash withdrawal request in a place that is unusual for the card owner or a sensor reading that exceeds the norms can be verified based on profiles or historical data. However, what happens when the event does not differ from the norm at first glance?
Multidimensional nature of events
Anomalies are not easy to detect. It is often the case that the values of the adopted characteristics subtly deviate from the correct distribution, or the deviation from the norm is only noticeable after taking into account a series of events and time characteristics. In such cases, the standard approach is to analyze the characteristics in terms of e.g. their mutual correlation. Mirek Mamczur elaborated on this very well in his post.
For our needs, we will generate an artificial data set where one of the classes will be considered anomalies. The events will have 15 characteristics and they will be clustered fairly close together with a standard deviation of 1.75.
To get the model to make an effort, we can force closer data generation by reducing [center_box].
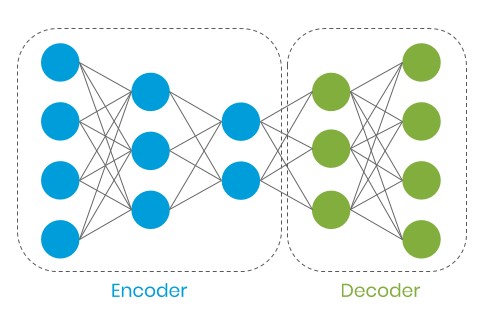
Autoencoder (undercomplete)
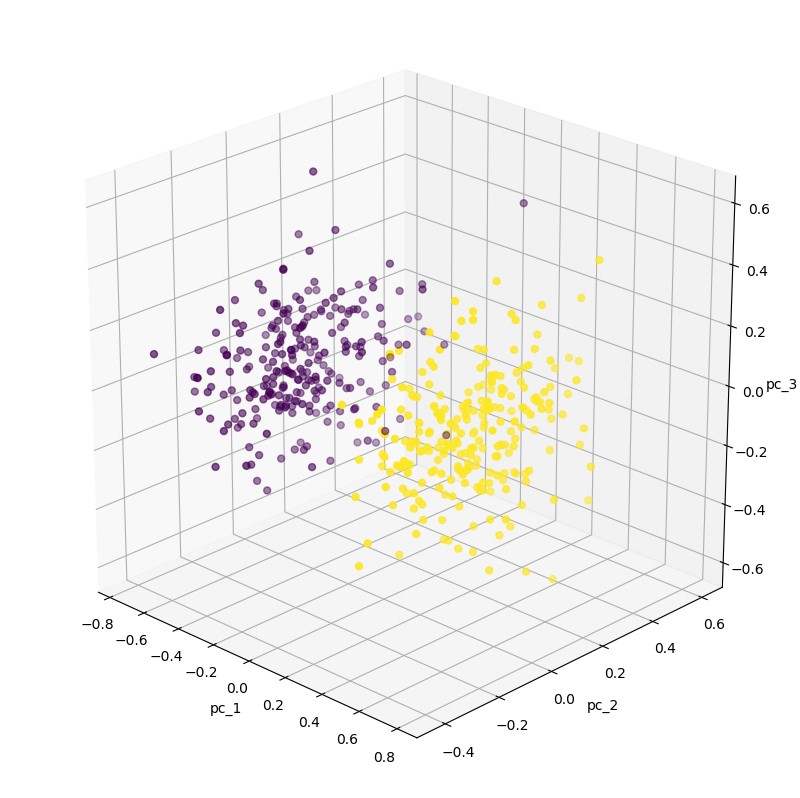
An interesting feature of this architecture is its ability to encode data into its representations containing fewer features (latent representation). During training, the measure of faithful reproduction of input data is defined by the reconstruction error.
Following this lead, when we define the correct events in our system for model training purposes, the model should extract features from them and reproduce the event with some approximation based on them. When an abnormal event appears in the model, the reconstruction error should be noticeably greater due to the different characteristics of the data.
Keras
Using Pandas we build a DataFrame containing test data. After scaling, 20% of it will be used for validation.
For some models and problems that they solve (e.g. CNN classification), increasing the depth can help extract more information from the data. Autoencoders that are too deep will learn to copy X into Y without building their compressed representation, which we care about. In our example, it is worth checking how the MSE will change when we increase the depth and reduce the number of neurons.
The model was trained over 100 epochs. Going above this value did not show a tendency for improvement and the result stabilized at
0.017–0.018 MSE.
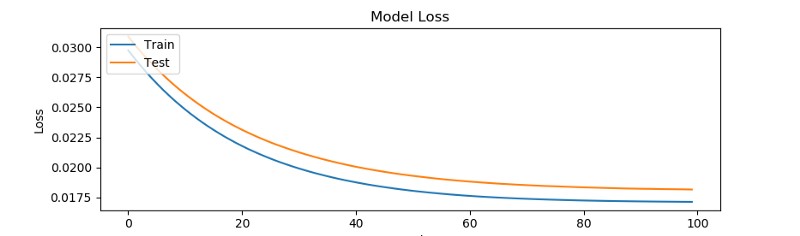
We will plot the cut-off threshold [threshold = 0.035], above which events will be classified as suspicious.
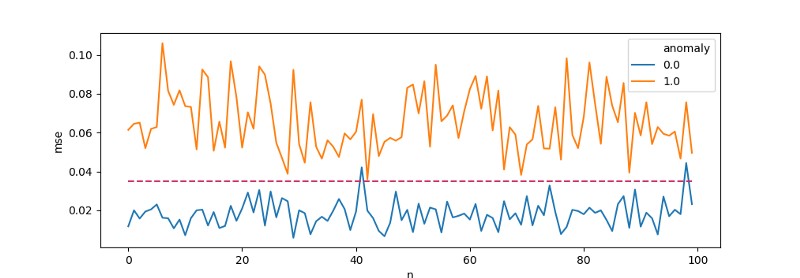
After some modifications, this block of code can be plugged into a system and serve as a validator. Everything within the MSE ≥threshold will be sent to a dedicated queue of suspicious events requiring analysis. The rest will be handled by the standard flow.
Summary
In the examples, I used an artificially generated data set for clustering. Data for two classes had features containing noticeable dispersion among themselves, which helped the model detect differences during training. In real situations, only some of the features will deviate from the norm. Autoencoders are one of the available possibilities when evaluating an event and should be used alongside other algorithms.
Further readings
- Deeplearningbook [Ian Goodfellow, Yoshua Bengio, Aaron Courville]
- Building Autoencoders in Keras [Francois Chollet]
Mateusz Frączek, R&D Division Leader