DL4J with Kafka Streams for Anomaly Detection
In my previous post we went over the topic of autoencoders. It is certainly knowledge worth implementing in one’s life. Let’s now imagine a system where the communication between servers is done using Kafka. During the lifetime of the system it turned out that some events are quite harmful. We must detect them and transfer them to a separate process where they will be thoroughly examined.
Let’s start with a few assumptions:
- We have 3 topics
[all_events] from which all events flow,
[normal_events] where we will forward the correct events and
[anomalous_events] where we will send suspicious cases. - Consumers listening on [normal_events] and [anomalous_events] are able to handle duplicates.
- We will process events in packets. Let’s assume a 5-second window during which we will aggregate everything that flows from [all_events].
These event packets will be forwarded to the autoencoder. - The project is carried out in Java and remains in the associated technological stack.
Event processing with Kafka Streams
Kafka Streams is a library that allows for processing data between topics. The first step is to plug into [all_events] and build a process topology.
- .groupByKey(…) : Needed to obtain KGroupedStream, grouping is performed by the record key.
- .windowedBy(…) : The definition of the time window that will wait for events for 5 seconds. When building aggregations, it is worth considering whether the problem of delayed events is important to us. Most likely if our model also relies on time characteristics, we would not want to lose events for a given time window.
- .aggregate(…) : Events that occur during the given time window are stored in one object, packaged for the event list.
- .toStream(…) : Kafka can operate on tables (this is the nature of our aggregation) and on streams. We switch to stream for the needs of further processing.
- .transformValues(…) : The crux of the issue, in this step the collected events will be forwarded to the model. The argument is EventsAggregate, and the result is a transformation of the event list with the label [NORMAL/ANOMALOUS].
- .flatMap(…) : The key built during aggregation is no longer needed. The result of the transformation is a full-fledged record with the original event and label as the key.
Filtering by key, events are directed to dedicated topics where they will be handled appropriately.
Autoencoder with DL4J
The library allows for the use of preset models built in Keras. This is a good solution when the AI team works at TF/Keras and they are responsible for building and customizing models. In this case, we will take a different route. We will create and train an autoencoder in Java.
The events have the same structure and values as in the example previously touched on. They are divided into two CSV files [normal_raw_events.csv] and [anomalous_raw_events.csv]
Incoming data is not standardized. We build a dedicated NormalizerMinMaxScaler which scales values to the range of [0.0-1.0].
The trained normalizer will serve as a pre-processor for a dedicated iterator that navigates the [normal_raw_events.csv] file.
The autoencoder will have the same structure as the previously mentioned example in Keras.
The model and normalizer are saved, ultimately they should end up on a dedicated resource from which the running application would download and build its configuration.
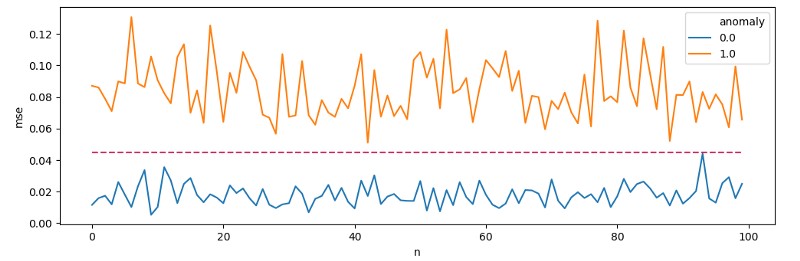
The trained model may show an average reconstruction error for typical events at 0.0188, while for anomalies the number will be 0.0834. By inputting MSE for 100 events from two groups on the chart, we can specify the cut-off threshold at [threshold = 0.045].
Kafka Stream Autoencoder Transformer
To map the model into the process topology I will use the ValueTransformer interface implemented in the AnomalyDetection class. In the constructor, we create a model with a normalizer and classes that will help with calculating the reconstruction error.
The transform method receives the events collected in the time window. They must be mapped to a format understandable to the [INDArray] model. For each of the events a reconstruction error is calculated, those that exceed the threshold receive the ANOMALOUS key.
Summary
- We assumed that event consumers can handle duplicates. This is a safe practice, but there could be situations where it will be difficult to realize. In such cases it is worth considering using the .suppress(…) method.
- The time windows will be buffered and the results will not be passed to continue down the process every 5 seconds. Rather, we will see aggregates flowing in packages every 30 seconds. For tests, we can modify parameters such as [CACHE_MAX_BYTES_BUFFERING_CONFIG] or [COMMIT_INTERVAL_MS_CONFIG] to try to get shorter times.
- When choosing a technology, consider aspects such as clustering, implementation cost, and available integration methods. It is possible that Spark or Flink will be a better solution.
Further readings
Mateusz Frączek, R&D Division Leader